Considerations for planning an Azure Data Factory enterprise deployment: what to release, how to deploy.
Azure Data Factory (ADF) is the native batch data processing service, aka ETL/ELT (Extract, Transform and Load), available in the Microsoft public cloud. In its v2 version (let’s forget about v1), ADF offers orchestration and data movement as a service. It’s quite good at that.

ADF offers multiple features that makes it a true cloud native ETL/ELT:
- an orchestration engine (via pipelines and triggers) that can call external services in addition to…
- …two native data movement engines: mapping data flows (poor name if you ask me since it has nothing to do with maps) running Spark under the cover and wrangling data flows that leverages the Power Query engine
- a metadata repository (linked services, datasets)
- a credentials manager (but let’s use Key Vault instead)
- a web IDE with debugging capabilities: the ADF UI
If all these functionalities empower single developers to get highly productive quickly, it makes things somewhat confusing when trying to standardize operations for larger teams.
Here we won’t talk about moving data round, but rather planning an enterprise deployment of Azure Data Factory.
Summary
There are 3 aspects to take into account when deciding how to standardize development practices in ADF:
- Deployment scope : What is the atomicity of a release:
- All-or-nothing deployments, a factory being deployed entirely every time, will rely on ARM Templates
- Something more subtle, scoped to specific artifacts, will be enabled by JSON based deployments
- Development scope : How to allocate factory instances, taking current ADF constraints into account, it boils down to:
- Can our development group share the same managed identity? Else we need to allocate one factory instance to each developer/team that needs their own identity
- Do we need triggered runs in development, or is debugging good enough? For the former we’ll need to dedicate a factory instance
- Infrastructure scope : Which artifacts are considered infrastructure and not code, and should be treated as such
- Self-hosted integration runtime (SHIR), the piece of software we need to deploy in private networks to operate there
- Credential managers, focusing on Azure Key Vault
Let’s jump into the details.
Deployment scope : atomicity of a release
ADF artifacts are defined in a JSON format. Here we’ll need to decide whether to deploy these artifacts via ARM templates (default approach, with a “build” phase to generate those templates) or to publish them individually instead.
ARM templates deployments are the ones covered in the documentation. They are supported natively in the ADF UI but only offer all-or-nothing deployments. They rely on the integrated publish process that builds ARM Templates (in the adf_publish branch) from the JSON definitions of artifacts (in the collaboration branch). Since there can be only one pair of collaboration-adf_publish branches per factory instance, this will impose constraints on the developer experience, as we’ll discuss below.
JSON based deployments require custom wiring and/or a 3rd party tool, but offer a-la-carte deployments. It’s an involved setup that brings a solution to a problem that in my opinion can be avoided by properly scoping and allocating ADF instances instead, as discussed below. We also need to be mindful about the fact that if it is straightforward to find what has been updated between 2 branches (master and release, via git diff), it is more complicated for what’s been removed (due to Git renaming “optimization”). This means that to enable JSON based deployments, we will need to build a script that prunes what has been deployed in Production. Never a good prospect.
Development scope : Factory instances allocation guidance
We are going to look at the constraints guiding our design, and how to plan our platform around them. This starts with a branching strategy.
Branching strategy
This being an enterprise deployment, we will use source control. ADF integrates with GitHub and Azure DevOps natively. We’ll use Azure DevOps in the rest of the article as the third party tool we might need lives there.
If we’re collaborating on a code base, using Git, then we’ll need to think about a branching strategy. Most of the issues we can observe in ADF enterprise deployments are solved by making a conscious choice about that branching strategy, and enforcing it.
I personally recommend the Atomic Change Flow approach from Charles Feval:
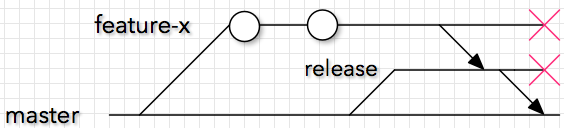
figure 1 : Charles’ diagram of the Atomic Change Flow]
The main difference with the simple one recommended by Microsoft, is that master always stays in sync with Production. We work on feature branches, merge them into a release branch that gets pushed through the delivery pipeline to production. We only merge the release branch back into master if/when the release is successful.
Please go read the full article. We will see how this will impact ARM Templates based deployments.
Design guidance
The following constraints, specific to ADF, will guide how we should distribute factory instances. Note that since factories only incur costs when used, there should be no impact cost-wise in distributing the same activities on 1 or N factories.
- A factory instance can only be wired to a single repository
- Multiples factory instances can be wired to the same repository
- A factory instance has a single managed identity
- A factory instance has a single
collaboration/adf_publishbranches pair. Thecollaborationbranch holds JSON artifacts, it is the source branch for the internal build process that generates (“publish”) the corresponding ARM templates in theadf_publishbranch (see schema)- The default
collaborationbranch is recommended to bemaster, but can be changed to a user defined branch- The
adf_publishbranch holds ARM templates from different factories in different sub-folders- Triggers can only be started from the collaboration branch
- We do not merge ARM Templates. Any collaboration must be done in JSON land
Point 1 will give us that we should distribute factory instances on repository boundaries. If we allocate repositories per { team x project x solution }, then each of these should get at least one distinct factory instance.
Points 3 and 2 will give us that we should also distribute factory instances on data source/sink authentication boundaries. If we generate individual credentials to each developers for linked services, then each developer will need a data factory instance to get their own managed identity. All of these factories are tied to the same repository, code is moved between branches via pull requests. On the other end, if we’re okay with those credentials being shared in a team, then a shared factory instance will do fine. Please note that this applies for services for which ADF has a connector supporting managed identities, others we will cover later when discussing Key Vault.
Points 7, 4 and 2 will give us that we should also distribute factory instances to prevent collisions of triggered runs with the release pipeline. If the team is fine with debugging (no triggers) there is no need here. If the team needs to trigger runs but is okay sharing an instance together then dedicate a factory for releasing (wired to the CI/CD pipeline) in addition to the development one (used for triggers). If each developer needs to trigger runs independently then allocate a factory instance per developer and add one instance for releasing. All of these factories are tied to the same repository, code is moved between branches via pull requests.
Deployment examples
Let’s illustrate that with a couple of examples, using ARM Templates deployments.
The most basic deployment will support a team working on a single project/repo, sharing a single managed identity (or not using the managed identity at all but sharing credentials anyway), and mostly debugging.
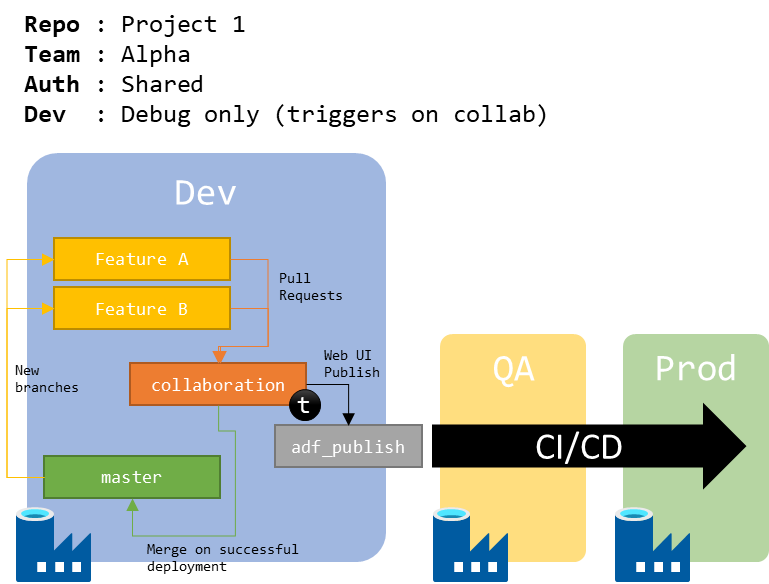
Figure 2 : Schema of 1 repo for 1 project, shared authentication, debug only setup
After some time, that team realizes that triggering runs in development means polluting the CI/CD pipeline with code that may not be ready to be released. A way to solve that is to put a release factory instance between the dev and QA ones.
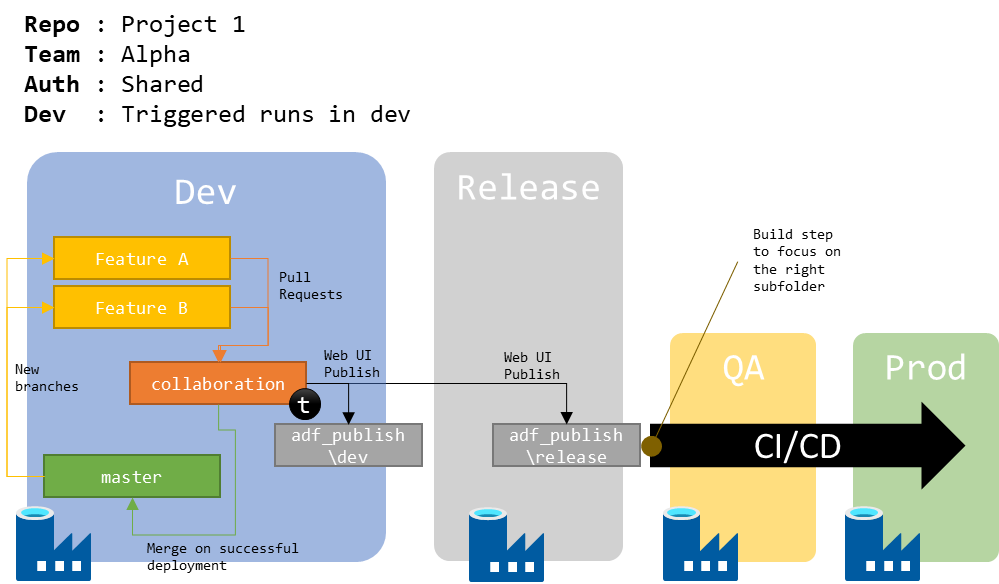
Figure 3 : Schema of 1 repo for 1 project, shared authentication, triggers enabled
Switching to another team, that requires individual managed identities for each developer.
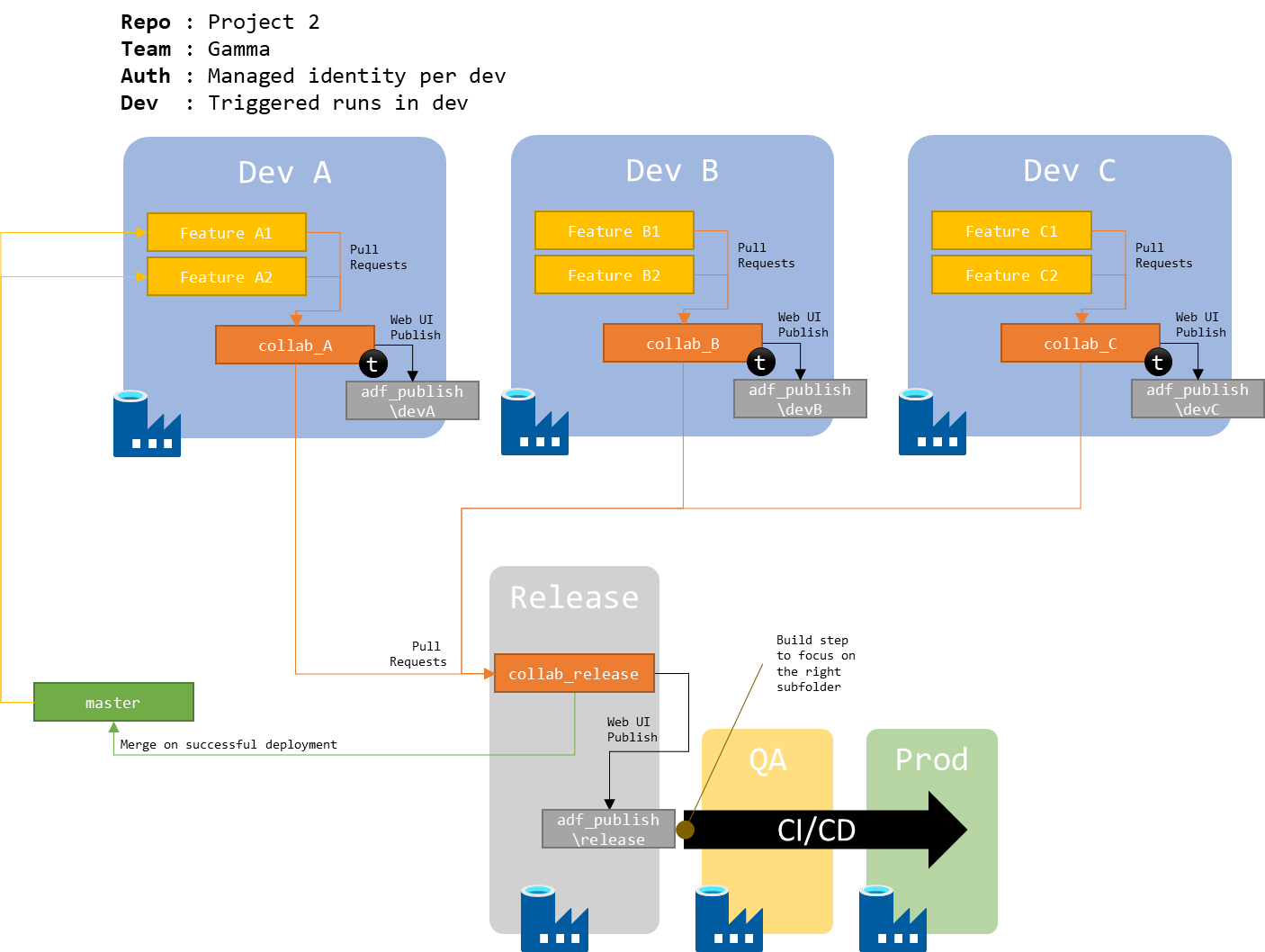
Figure 4 : Schema of 1 repo for 1 project, individual authentication
We can see that the branching strategy we choose has a deep impact on the overall setup. Above, master is protected from the current release work, we can regenerate release candidates or feature branches from it in case anything goes wrong.
Infrastructure scope
Self-hosted integration runtime (SHIR)
We won’t cover what are SHIR, why they are needed or how to deploy them. Instead we will focus on how to set them up in our topology.
Here are the design considerations we are working with:
- A SHIR is an agent first installed on a machine (VM, on-prem server…), then registered to a single factory instance
- In the repository, a SHIR registration is just another JSON artifact, located in the
\integrationRuntime\sub-folder. It’s quite minimalist ({"name": "shir-name","properties": {"type": "SelfHosted"}}), which means the actual wiring happens under the cover, hidden from us - Once created in a factory instance, a SHIR can be shared with / linked from other factory instances
Before going further, let’s remember that there is currently no graphical UI to change the registration of a SHIR agent running on a machine. But there are scripts located in the install folder (something like
C:\Program Files\Microsoft Integration Runtime\X.Y\PowerShellScript\RegisterIntegrationRuntime.ps1, use-plus tab/autocompletion to discover parameters). Very handy if we need to update a registration.
SHIR for single factory setup
When we have only one development factory instance (so not even a release one), the only dimension we have to manage are the environments: are we re-using the same SHIR across dev, QA and production, or are we deploying multiple ones?
If we want each environment to have its own dedicated SHIR (so 3 environments means 3 distinct agents, installed on 3 distinct machines), then we must only make sure that they share the same name. Then the minimalist JSON definition will go through the release pipeline untouched.
Each factory will have to go through the process of registering its own SHIR, since the underlying wiring still needs to happen.
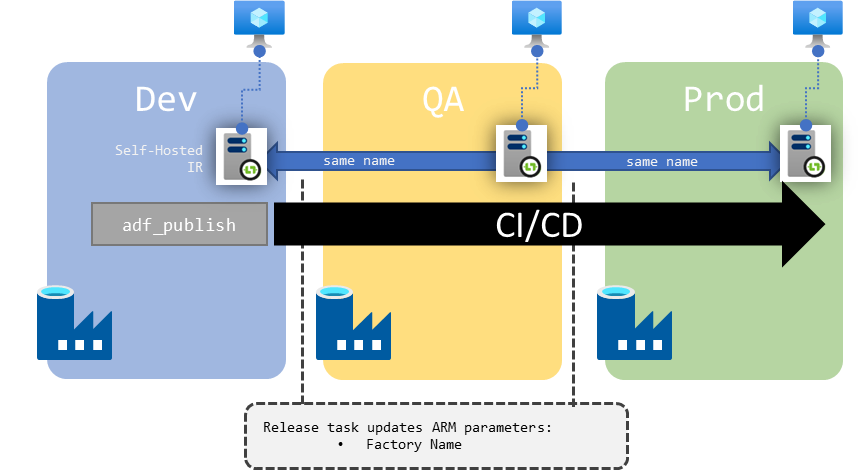
Figure 5 : Schema of one SHIR per environment for a single dev factory instance
Now if we want to re-use SHIR across environments, we need to switch to shared mode across the board. It’s easier to do so than to mix shared and dedicated, since the JSON definition structure is different, and would require some scripting to be altered in the release pipeline.
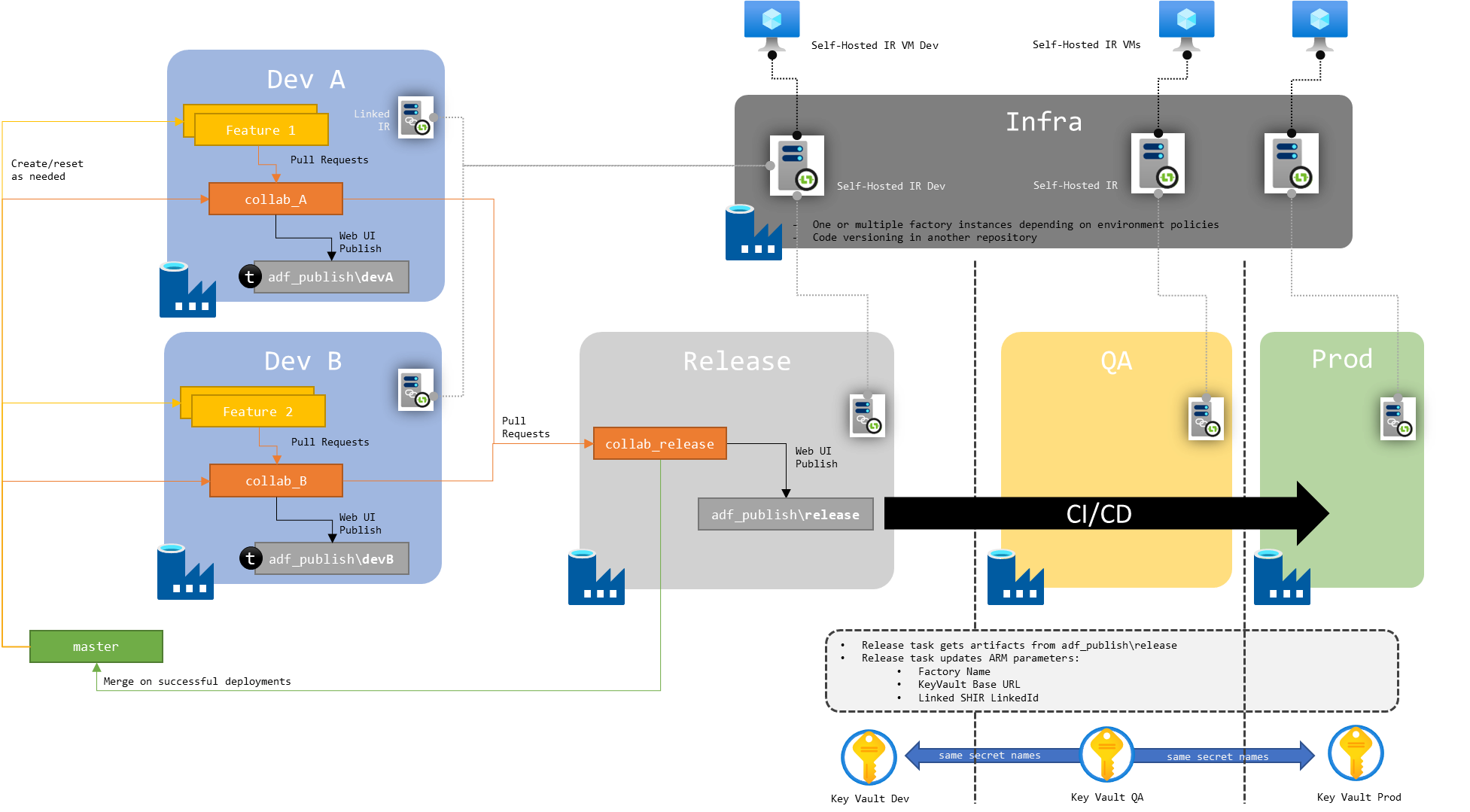
We can deploy the shared SHIR in one or multiple infrastructure factory instances. This is done to be able to store their definition in a separate repository, isolated from the release pipeline. The release pipeline will update the SHIR LinkedId property to point to the right SHIR when moving through environments.
Here also, each factory will have to go through the process of linking the SHIR, since the underlying wiring still needs to happen.

Figure 6 : Schema of shared SHIR across environments for a single dev factory instance
I expect most deployments to use shared SHIR in dev/qa, and a dedicated (but still shared) one for production, to better isolate workloads. This is the most resource effective and most future proof setup, for a little added complexity.
SHIR for multiple factory instance setup
We will have similar options when addressing multiple development factory instances:
- provision a SHIR for each factory in the development scope and each environment
- or share them across the board from an infrastructure factory(ies)
The thing is we don’t deploy SHIR in complete isolation: most of the time they are tied to a Key Vault deployment. We’ll talk about Key Vault later, but here we have to note that a limitation of how ADF currently handles Key Vault makes the full dedicated SHIR option moot, in my opinion.
Trying to make things short:
- The benefit of dedicating SHIR to each factory instance would be to allow for each developer to get a distinct networking path to their own data sources
- That implies that each developer use different physical data sources for the same logical one, and not just different credentials
- The same table is actually loaded from different servers depending on the developer. That’s original but why not?
- Which means we are serious about security, which means we are using Azure Key Vault to store those secrets (and not the native ADF option)
- But there is currently no way to dedicate a Key Vault instance the same way we’re dedicating SHIR (a benefit of their hidden wiring)
- So the developers can only read secrets coming from the same Key Vault
- Since we’re using a single repository, that means the same secrets
- Which breaks the whole equation
Currently the only solution that satisfies these unusual requirements would be to stop using the same repository in ADF.
Moving on, we can focus on sharing SHIR. As before, we will deploy the shared SHIR in one or multiple infrastructure factory instances. The release pipeline will here also update the SHIR LinkedId property to point to the right SHIR when moving through environments.

Figure 7 : Schema of shared SHIR across environments for multiple dev factory instances
Overall I think this is the most convenient setup for most teams.
Azure Key Vault
Another important piece of the puzzle is Azure Key Vault. We won’t discuss why and how to use Key Vault in data factory, only how to set it up in our context.
Key Vaults are declared as linked services in ADF. The JSON declaration file is located in the \linkedService\ sub-folder. Its format is simple (a name and a baseUrl pointing to the Key Vault instance https://<azureKeyVaultName>.vault.azure.net"). To be noted that Key Vault linked services leverage the managed identity of the factory instance for authentication. When handling multiple factories, we should automate that registration.
We will leverage Key Vaults to store the credentials of data sources that don’t support Managed Identity.
Since there is currently no way to dedicate Key Vaults to factory instances sharing the same repo, we will have to share those credentials in development wether we share factory instances or not. Because contrary to SHIR, there is no hidden wiring for Key Vault linked services: the baseUrl value is stored in the repository. Maintaining different values for each developer, the release and master branches through the feature lifecycle is certainly possible but will be painful. I’m lobbying the ADF team to either get Key Vault linked services a hidden wiring like SHIR, allow us to source their baseUrl from global parameters, and/or allow us to lock JSON declaration files in the ADF UI so their value is not saved to the repository but kept local. We’ll see how that goes.
The release pipeline will update the baseUrl property to point to the right Key Vault instance when moving through environments. For a single development factory instance setup:
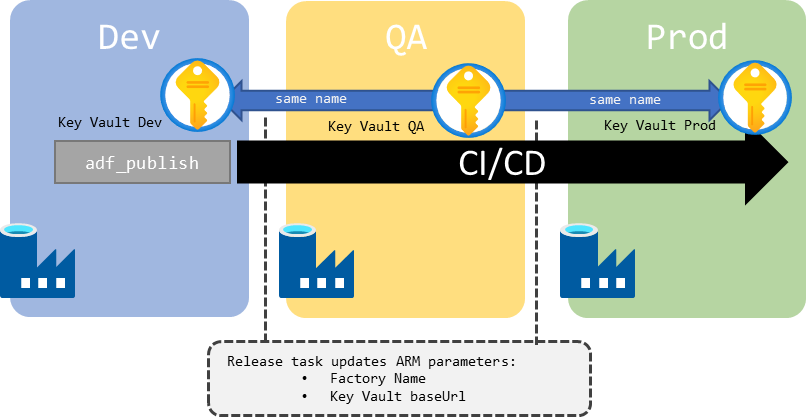
Figure 8 : Schema of Key Vault wiring across environments for single dev factory instance
Global picture
Finally, here is a global picture of dedicated development factory instance setup, with shared self hosted integration runtime and Key Vault:
Conclusion
The steps to planning an enterprise deployment of Azure Data Factory are the following:
- Define a branching strategy
- Understand what is infrastructure and what is code, design the right lifecycle for each
- Understand the options and pick a deployment scope. Most should use ARM Templates
- Understand the options and pick a development scope, primarily depending on requirements around triggers and managed identities
- Define an infrastructure topology
- From there, design the factory instance distribution model
- Go through the entire lifecycle of features and releases and check that nothing in ADF will prevent it to flow freely (see Charles’ article above on how to deal with issues)
Note that this will not be a unique combination for the entire organization, but rather a process that should be repeated for every ADF project/team.
